What the History of Software Development Tells Us about the Hurdles to Enterprise Adoption of LLMs
By JooHo Yeo and Matt Kinsella
Generative AI is predicted to add up to $4.4T of value to the global economy annually, according to a McKinsey study. However, enterprise adoption of the technology has been slow and mostly in the experimentation stage. A recent survey by Menlo Ventures showed that enterprise investment in generative AI is still surprisingly small ($2.5 billion) compared to those of traditional AI ($70 billion) and cloud software ($400 billion).
So, what is preventing enterprises from mass adoption of LLMs?

To answer this question, we looked to history as well as 35 ML engineers working on LLM applications in enterprises.
We believe a shortage of quality options for engineers to test and evaluate models and applications throughout the LLM App Development Life Cycle is a significant blocker to adoption and thus, a great opportunity for startups to address.
Traditional Software Development Life Cycle (SDLC)
The advent of modern software development processes can be traced back to the 1970s when Dr. Winston Royce made the first reference to the Waterfall model in his paper titled “Managing The Development of Large Software Systems.” This method defined software development into a series of sequential phases where each phase depended on the outputs of the previous one, similar to manufacturing processes of the time. The model quickly gained support from managers because of the structure it brought to software development, ensuring there was a clear spec to follow.

However, the model had its limitations such as the inability to take feedback from users and risking the entire process by delaying testing. Software development also started to change with the rise of the Internet. As expectations grew to bring software to market faster (along with the development tools and platforms to enable the increased pace), the rigidity and overhead of the Waterfall model became a hindrance to developer velocity. In 2001, a group of 17 developers published the “Manifesto for Agile Software Development,” a document that outlined the 12 principles of Agile development. This model revolutionized software development by emphasizing iterative releases that adapt to evolving requirements. This shift discarded rigid structures in favor of enhanced collaboration between development teams and business stakeholders. Shipping Minimum Viable Product (MVP) and iterating became a core part of the Agile methodology.

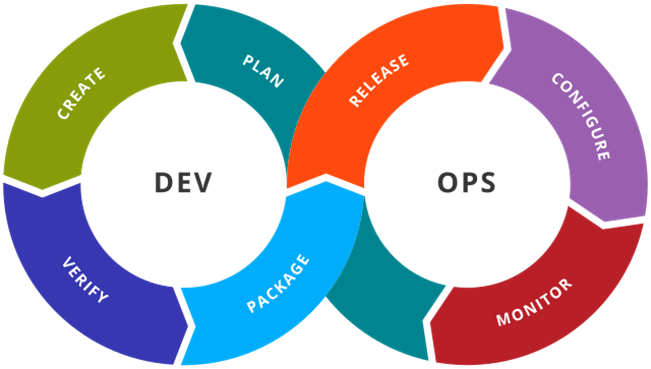
As the Agile methodology took off, a new challenge arose: operations had to be able to deploy and deliver software to users at a rapid pace. Based on his observations of the need for more synergy between development and operations teams, Patrick Debois coined the term “DevOps” in 2009. The objective of DevOps was an extension of the Agile methodology: to facilitate continuous delivery of features, bug fixes, and updates. DevOps necessitated a harmonious collaboration between traditionally separated units — development, quality assurance, operations, security, and more. In order to bring these functions together and deliver continuously to users, new steps were required.
The rise of DevOps tools contributed to software eating the world (as Marc Andreesen phrased it) in the 2010s. By the end of the 2010s, “every enterprise became a software company.” The global spend on enterprise software grew 129% over the decade, from $269B in 2011 to $615B in 2021. DevOps tools fueled the developer productivity needed to support the cloud and mobile platform shifts. With client expectations for reliability rising, tools that addressed testing and monitoring needs were especially critical for growing enterprise adoption.
As the software development life cycle matured, each step gave way to successful startups. Here are just a few:
Machine Learning Development Life Cycle (MLDC)
As Machine Learning came into mainstream software development, it had different requirements from traditional software development, making it challenging to apply and scale ML solutions to business applications. In 2015, the term “MLOps” was coined in “Hidden Technical Debts in the Machine Learning System,” a research paper that brought the aforementioned problems into the spotlight.
- Data collection, annotation, and curation were introduced as critical steps. Labeled data became crucial to training and evaluating models.
- Model training and evaluation across various model types required iteration and collaboration among stakeholders. Models need to be assessed for their accuracy and compared against each other in an objective manner.
- Post-deployment, models need to be continuously monitored for reliability and accuracy, whereas for traditional software, the need for maintenance was solely on reliability. Various changes in the distribution of the training, validation, and production data can happen overtime degrading the performance of the predictions.
A fresh set of companies arose to support these new developer needs.
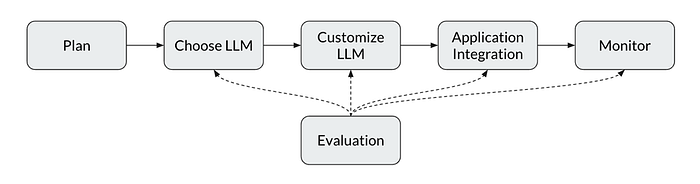
LLM App Development Life Cycle (LLMADC)
Akin to Machine Learning, LLMs have changed how applications are developed. Most notably, the data barrier has been knocked down. Developers no longer need upfront troves of labeled data to train ML models. The pre-trained LLMs are sufficient for demos and even some MVPs. However, data is still necessary for evaluating not only the outputs of the customized models, but also those of the overall LLM application.
Text generation tasks are also much harder to evaluate than classification tasks. Classification tasks are either correct or incorrect, whereas generated text has multiple dimensions to be evaluated on like factual consistency, relevance, and coherence. It is a difficult task to not only comprehensively assess output quality, but also weigh them systematically to be helpful in the comparison.
As LLMs can take unstructured data as inputs, the applications run the risk of behaving unexpectedly based on unexpected user inputs. The need to monitor and evaluate how the user interacts with the LLM application becomes even more important.

What Actually Is Testing, Evaluation, and Monitoring?
Development teams need methods to assess and enhance the quality of their projects. Testing tools help developers gather information about their software’s functionality, usability, and performance. Some examples of testing tools include tools for integration testing, bug tracking, automation testing, and performance testing. Beyond testing, these tools encompass broader test management solutions that feature collaborative functions that facilitate effective communication between testers and developers.
Evaluation tools help teams during the development phase to deploy different versions and choose the best variant to ship to production. Evaluation measures and compares various business metrics that are important to the company, like conversion rates or customer engagement. This allows software engineering teams to translate their technical progress into business value, creating a common language between all teams.
Monitoring and observability tools help ensure that software run reliably in production. Monitoring refers to watching a set of metrics to detect failures and performance issues. These performance metrics include network traffic, latency, and error rates. Monitoring tools provide information about what happened. Observability takes the concept of monitoring a step further and equips engineers with logs and traces to understand the root cause of problems. Observability tools offer the insights into why the issue occurred and how to fix it.
Testing, Evaluation, and Monitoring Have Historically Been Large Markets
Testing, evaluation, and monitoring have always been critical for companies that offer software products. While all steps of the software development process are important, ultimately the objective of developing software is to deliver value to users reliably. As a reflection of its significance, testing has been a large portion (20–30%) of enterprise software development budgets.
Especially with the shift of software testing from manual to automated, software unicorns like Browserstack, Postman, and SmartBear have been able to capitalize on increasingly faster and comprehensive testing needs. The automated testing market is $15B and is projected to grow at a CAGR of 18.8%.
Beyond testing during the software development process, it is essential for businesses to monitor their software post-deployment to make sure it is operating as expected. As cloud infrastructures have gotten more complex, observability solutions have become essential in debugging reliability and latency issues as well as removing them proactively. Observability products can also help businesses better analyze and thus, reduce their infrastructure spending. According to Honeycomb, companies spend up to 30% of their infrastructure costs on observability. Several multi-billion dollar companies have emerged in this space including Datadog, New Relic, and Dynatrace.
Companies are looking further than just ensuring functionality and now measuring the value their products deliver and quantifying the ROI of their software projects. The market for online evaluation software, including AB testing software, is over $1B with companies like LaunchDarkly, Optimizely, Split.io, and Statsig.
For LLM app development, evaluation and monitoring will continue to be critical and new companies will spring up in this space. To understand what the future looks like for the LLM evaluation, we surveyed 25 ML practitioners working at large companies[JO1] [JY2] (with over 20 developers) that are developing genAI-powered products. In addition to the survey, we also conducted interviews with 10 engineers in this space.
Survey Results
We asked experts to rank their top barriers to deploying LLMs to production from one to six (one being highest and six being lowest).
More than a third of the experts cited “evaluating model quality” as the top barrier for deploying LLMs to production. When looking at the average rank of each barrier, we see the same sentiment of model quality evaluation being the number one concern.
These quantitative results were in line with the learnings from our expert interviews where engineers emphasized the importance of mitigating hallucination, especially for developing software in regulated industries like finance and healthcare which have low tolerance for error.

Barriers of Deploying LLMs to Production (average rank)
1) Evaluating model quality (2.04)
2) Data privacy and security (3.08)
3) Testing and QA (3.48)
4) Costs of training and serving (3.72)
5) Model reliability (3.84)
6) Data pre-processing for ingestion (4.92)
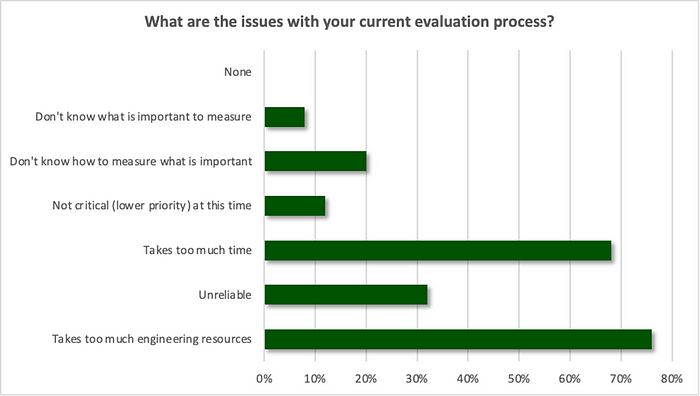
LLM evaluation is currently a time-consuming process. When asked what percentage of their time they spend on testing and evaluation, respondents said that they spend 35%. In addition, the top issues with their current LLM evaluation process were that it takes “too much engineering resources” (76%) and “too much time” (68%).
There are two reasons why evaluation is currently a time sink.
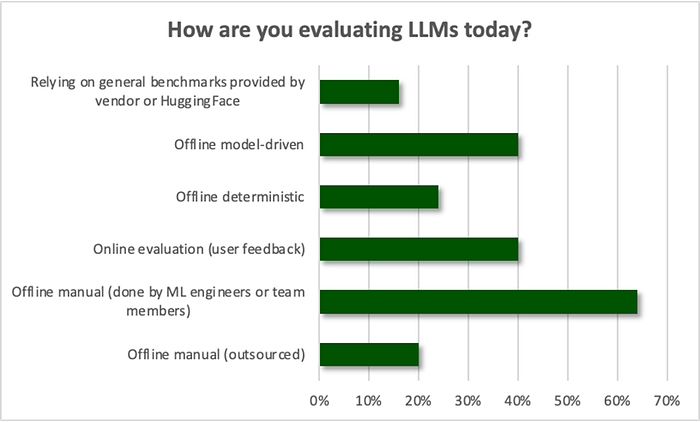
1) The process is manual. At 64%, offline manual evaluation (done by ML engineers or team members) was by far the most common form of evaluating LLMs noted by practitioners. This is consistent with the many times we heard of “eyeballing” as a “good enough” solution from our interviews. The lack of tooling and standard process also leads to repetitive work that makes the experience even more time consuming.
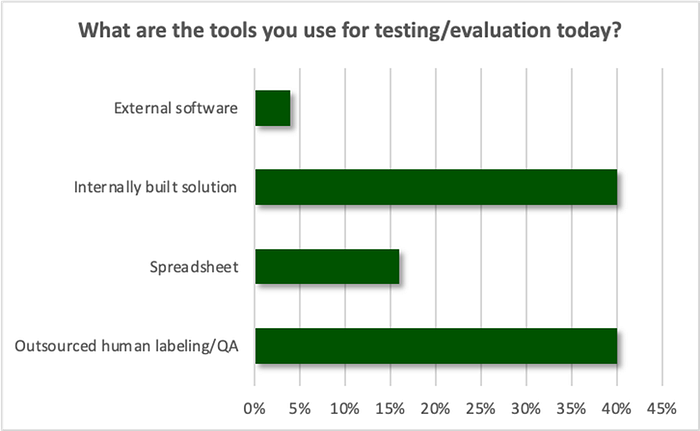
2) Stitching together tools ad-hoc is time consuming and unscalable. 40% of respondents said their organization uses an internally developed solution for testing and evaluation, while only 4% said they are evaluating external solutions. The lack of available external options have driven companies to build their own solutions. For example, a large tech company spent nine months of precious time of eight engineers to develop an internal evaluation platform. To build and maintain LLM evaluation tooling can be a significant engineering lift.
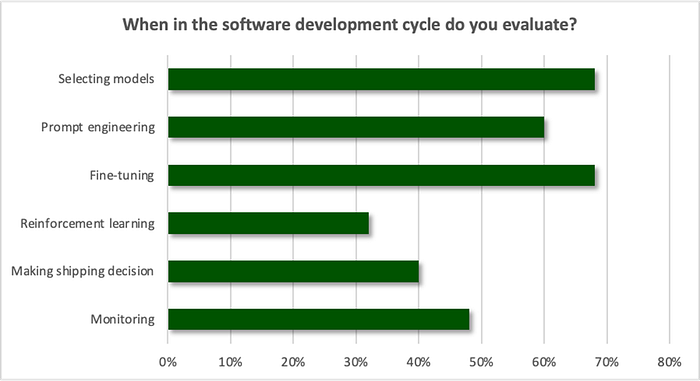
From selecting LLMs to monitoring the application in production, evaluation affects each stage of the LLM App Development Life Cycle. 80% of respondents said they perform evaluation at more than one stage of the process, with 68% replying that they evaluate during at least three out of the six major steps listed below. In LLM app development, evaluation and testing is no longer a single step, but continuously executed.
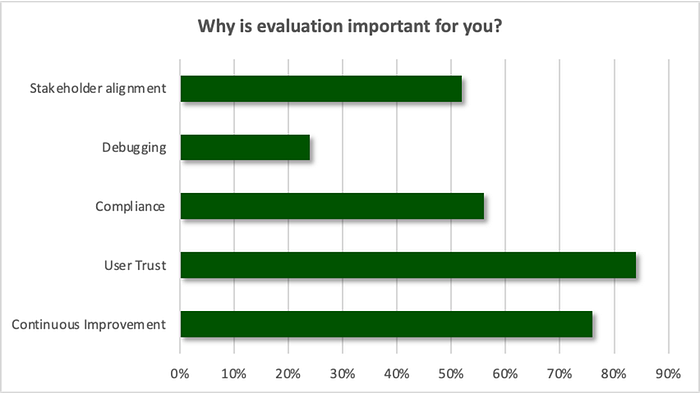
When asked why LLM evaluation is important, experts responded with user trust and continuous improvement as the top two responses (84% and 76% respectively). While utilizing the power of evaluation to enable iteration ranked highly, only 40% use evaluation to make shipping decisions, pointing to a gap of processes and tools today. In fact, the highest response to the question of the effect of the lack of testing and evaluation was lack of confidence in the product (86%). While LLM-based app development is still in its early innings, we believe that evaluation will bring the confidence to supercharge innovation.
As mentioned before, very few companies are currently using external tools for evaluation.
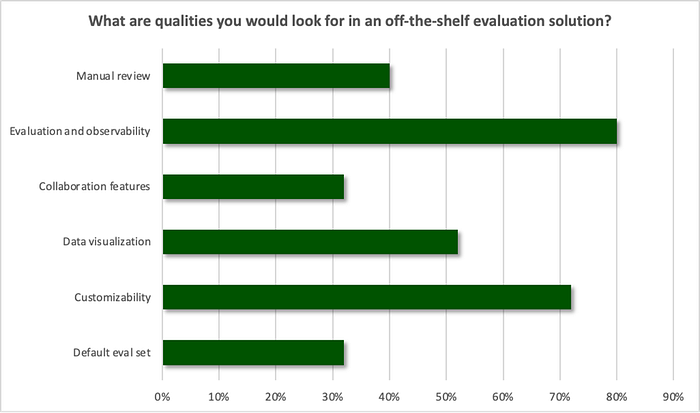
Through the survey and interviews, we tried to get an understanding of what their criteria was for off-the-shelf solutions.
What we heard consistently was that engineers are searching for an all-in-one solution that covers everything from testing in development to monitoring in production. “Evaluation and observability” ranked the highest (80%) when asked what qualities are considered when considering external options. Buyers are not looking for point solutions, but rather an end-to-end solution that can support all parts of the workflow. We also believe that the practitioners prioritize observability because it is harder to predict how users will interact with LLM applications due to the unconstrained input space. Therefore, while offline evaluation to inform engineers during the development process are table stakes, online evaluation capabilities will also be necessary.
The second highest desired quality was customizability (72%). While default test sets and metrics are helpful, practitioners are looking for solutions where they can also add testing and evaluation methods specific to their business needs. This result is unsurprising as many engineers have voiced frustrations about the unreliability of generic benchmarks to assess the potential of LLMs in their specific use cases. For external solutions, buyers will be looking for industry and application (i.e., summarization, Q&A, etc.) specific data sets, test cases, and evaluation metrics. Generating test cases based on subject matter expert inputs and actual user inputs will also help meet these customizability needs.
LLM Evaluation Market Size Estimation
While we are still at the beginning of LLM app development, we believe that there is a multibillion dollar market opportunity in evaluating LLMs based on our study of software development history and practitioner input.
Based on our survey, 96% of respondents indicated willingness to pay for an external LLM evaluation product. Approximately half of the respondents were in the $10–50K and $50–100K buckets, which was consistent with the contract sizes that LLM evaluation startups we spoke with were closing with their smaller-sized clients. LLM evaluation software providers are observing six-figure contracts as they start to engage with commercial and enterprise clients, which is also reflected in the survey responses as over a third of respondents indicated that they are willing to pay six to seven figures.

To estimate the market size of LLM evaluation, we calculated the weighted average of the survey responses, which was approximately $326K. There are many different ways to think about how large the target customer base could be:
1) According to Gartner, more than 80% of enterprises will have used genAI APIs or models, and/or deployed genAI-enabled applications in production environments by 2026. If we define enterprises as companies with over 1000 employees, there are around 8000 enterprises in the USA.
2) According to Tracxn, there are approximately 14,700 AI companies in the USA.
3) During Microsoft’s October 2023 earnings call, Satya Nadella said that more than 37,000 organizations subscribe to Github Copilot for Business.
Taking the most conservative approach of option one (80% of 8000 enterprises), we can estimate a domestic market size of approximately $2.1B.
Another methodology of estimating market size is by looking at enterprise budgets. Menlo Ventures estimated that enterprises spent approximately $2.5B on genAI in 2023, while all AI spend was about $70B. Since companies have allocated 20–30% of software development budgets for quality assurance and testing in the past, we can expect the LLM evaluation budget to be in the $500M-750M range. If the enterprise LLM spend grows at a double-digit CAGR following the LLM market growth rate, we can expect the LLM evaluation market size to surpass $1B in the next few years.
Why LLM Evaluation is Holding Up Adoption:
Evaluation is the bottleneck throughout the development life cycle. Compared to the sexier parts like model training and deployment, testing/evaluation may seem boring, but they are critical to supporting each step of the LLM app development life cycle, from model selection to experimentation and finally, to monitoring. Companies are looking for solutions that can provide capabilities at each step over point solutions. Consistency is key for versioning and unified form of assessment.
- Langfuse is a startup offering testing and evaluation solutions from the proof-of-concept phase to full rollout. Their model- and framework-agnostic product tracing feature makes it easier for engineers to debug throughout the development process. While some might argue that it is too early for enterprises to think about observability, Langfuse is building a data architecture to support the whole LLM app development life cycle for the needs that will inevitably come.
Generic LLM benchmarks are insufficient to evaluate for specific business use cases. Even disregarding customizations, a LLM may perform very differently across general tasks vs specific business use cases. To borrow David Hershey’s analogy, benchmarks are like SATs: they are helpful in assessing one’s skills in a range of subjects. But what matters to enterprises are the job interviews: how the candidate performs on tasks pertinent to the specific business use case in that environment.
- Startups like Patronus AI can give enterprises more confidence in deploying LLMs by generating adversarial, comprehensive test cases and scoring model performance in specific, real world scenarios.
- Industry-specific datasets could be an initial edge for the evaluation providers. Patronus AI released FinanceBench (a high quality, large-scale set of 10,000 question and answer pairs based on publicly available financial documents) to be a first line of evaluation for LLMs on financial questions.
Among offline evaluation methods, human evaluation is the most common, but manual review is expensive, slow, and vulnerable to human error — all factors which slow down the development process. Deterministic and model-driven evaluation can be cheaper, faster, and provide unbiased alternatives. Shortening iteration cycles can accelerate software development.
- As mentioned in the survey analysis section, companies that have built internal solutions have experienced the large time and human capital investment required to build a comprehensive evaluation platform. Maintaining these internal tools in the LLM world, where models, architectures, and even evaluation methods frequently change, requires significant expertise and overhead. Buying an external solution can relieve development teams from these headaches.
- Confident AI provides a Pytest for unit testing LLM applications (called DeepEval), which supports various metrics such as hallucination, answer relevancy, RAGAS, etc. Confident AI is also implementing state-of-the-art (SOTA) LLM-based evaluation approaches, like G-Eval, and building proprietary multi-agent-based evaluation methods (JudgementalGPT) to address limitations of LLM-based evaluation like position and verbosity biases.
- Currently, there is a block in running automated evals at scale with SOTA models due to cost and latency concerns. Evaluation startups like HoneyHive AI are investing in R&D for evaluation-specific foundation models that can be used to run as offline and online evaluators, delivering performance in line with GPT-4 at a fraction of the price and speed.
The unpredictability of how users will engage with LLM products is a challenge for enterprise software, where there is little room for error. Online evaluation becomes especially important to understand how users engage with the product and get ahead of quality issues.
- Startups like Athina AI are now running topic classification on user queries to help clients understand how models perform live on different types of queries.
- Ultimately, what matters to companies is how much value the LLM products are delivering to the users. To measure the impact of the LLM products on the business-wide KPIs, A/B testing platforms like Statsig and Eppo can be utilized.
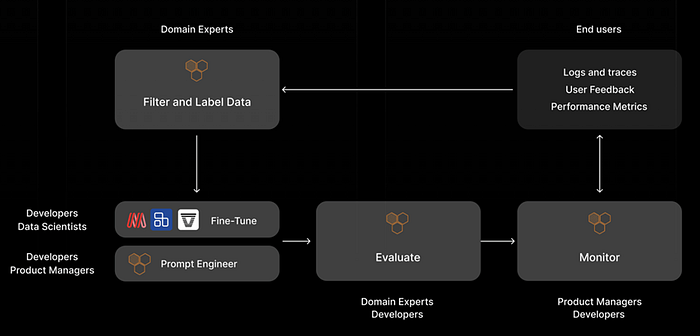
The evolved needs of various stakeholders within organizations require a new solution.
- LLM applications are not only developed by traditional ML practitioners, but also increasingly by product engineering teams and generalist software engineers. Compared to traditional software development, non-technical stakeholders, like product managers, are also more easily able to plug themselves into the development process steps like prompt engineering and monitoring. Inputs of subject matter experts are also vital perpetually across the LLM app development cycle. The shift in workflows is addressed today by stitching together various disconnected tools such as spreadsheets, internal dashboards, and product analytics software, which causes inefficiencies and risks. Companies like HoneyHive AI are building a unified workflow addressing each of these stakeholders’ new workflow needs that enable seamless collaboration among all parties.
Why Evaluation Will Become More Important Over Time:
Based on our interviews, we have seen that engineers working at enterprises are currently focused on shipping MVPs that are driven by top-down influence.
- In order to iterate (to reduce costs, improve accuracy, and provide additional value to users), companies will need the ability to consistently track performance and experiment in parallel.
- Articulation of ROI will be paramount for further investments.
Rising complexity created by an increasing number of stakeholders and their diverse backgrounds (both technical and non-technical roles) will make eyeballing and tracking with spreadsheets impossible to scale.
LLM systems are “fragile” because of the quickness at which new models and architectures are introduced as well as other dependencies. Without rigorous tests at the unit and system level, things are bound to break and take up already scarce ML engineering time.
- Reliance on models that are pre-trained by other companies creates risks that enterprises are unlikely to take on. Enterprises will not want to rely on communication from model providers to understand these risks like model unavailability and updates to models.
- To support evolving complexities of LLM application architectures, startups including UpTrain are going beyond offering basic evaluation of the quality and appropriateness of response and retrieved-context. They are building capabilities to judge the quality of AI-driven conversations and the correctness of AI agent actions.
While proprietary models like OpenAI and Anthropic dominate, the trend is moving towards companies using multiple models (even startups that route prompts to the best model based on use case, like Martian, are starting to pop up). The OpenAI scare last November led to hundreds of OpenAI customers reaching out to its rivals over just that weekend.
- With multiple models used, the need for choosing, experimenting, and monitoring will increase. The increasing complexity of model choice and architecture lends to more need for evaluation.
Market Map of LLM Evaluation Startups
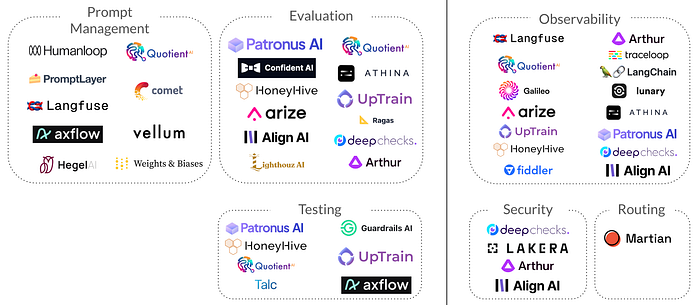
This is a non-comprehensive visualization of startups that are working in the LLM Evaluation space bucketed by problems they address. The line denotes a distinction between development and production stages. Security and Routing were also included as needs adjacent to evaluation engineers face in the production stage.
Final thoughts
Thought leaders are predicting that 2024 will be the year when we will see companies move from prototype to production for genAI adoption. Matt McIlwain @ Madrona put nicely that the shift will be from “‘Let’s Try’ to ROI.” Evaluation will be the first step required to assess ROI for past projects and forecast investments needed for future projects.
While genAI MVP projects were driven by top-down decisions, the LLM app development process will mature similarly to the systematic traditional software development process. In order for mass enterprise adoption to happen, the process will not only require quantitative data for objective comparisons, but also extensive collaborative capabilities for stakeholder alignment. These additional needs will make the already time-intensive evaluation process even lengthier unless there is tooling to support them. The ability to explain metrics will become critical to bringing diverse stakeholders to agreement.
Evaluation needs will become increasingly more industry- and application-specific, while general evaluation benchmarks will be suggestive at best. As companies continue to customize LLM applications for their evolving business use cases, the ability to tailor tests and evaluation metrics will be imperative.
We are optimistic about startups in this space because enterprises have expressed positive initial signals for buying rather than building. Based on our survey and interviews, we have validated how much of a pain point evaluation is, how troublesome it is to build an internal solution, and how high the willingness is to pay for an external solution. Additionally, startups offering evaluation tools are saying that they are experiencing a wave of inbounds this quarter. We are excited to continue to follow this space closely.
We’re looking to learn from pioneers who are leading the future of LLM evaluations. If you are building a LLMOps startup or contributing to the evolution of the LLM App Development Life Cycle in any way, we would love to chat! Please reach out to Matt Kinsella (Matthew.Kinsella@maverickcap.com), JooHo Yeo (joohoyeo@stanford.edu), or both of us!
The views expressed herein are solely the views of the author(s) and are not necessarily the views of Maverick Capital, Ltd. or any of its affiliates. This article is not intended to provide, and should not be relied upon for, investment advice.
Appendix
Survey Results